
Whether you’re deciphering stock market trends, understanding customer behaviors, or predicting climate patterns, predictive analytics equips you with the tools to navigate the uncharted waters of the future. Modern predictive analytics depends on predictive models. The accuracy of your predictive model depends on the quality of your data, your choice of variables, and your model’s assumptions.
In this article, we dive into the world of predictive modeling, where we’ll describe the seven key techniques that help you anticipate the future with data-driven insight. We begin with the two most popular predictive modeling techniques: regression and neural networks.
1. Regression: Paving the Way for Predictive Insights
At the heart of predictive modeling lies regression. It’s the art of uncovering relationships between input variables and continuous numerical outcomes. Whether it’s predicting sales, stock prices, or temperatures, regression models shine in fields like finance, economics, and engineering.
Linear Regression: The Power of Linearity
Linear regression assumes a linear connection between input and output variables. It’s like drawing a straight line through data points to predict future values. This simplicity brings impressive predictive power and ease of interpretation.
Polynomial Regression: Navigating Non-linearity
But what if the relationship isn’t linear? That’s where polynomial regression steps in. It tackles curvatures by fitting higher-degree polynomial functions, adapting to more complex patterns.
Logistic Regression: Unraveling Binary Outcomes
Don’t let the name fool you—logistic regression isn’t just for regressions. It’s your go-to for binary classification problems. Whether it’s spam or not spam, 1 or 0, logistic regression excels in drawing the line between two categories.
2. Neural Networks: Unleashing the Potential of Complex Patterns
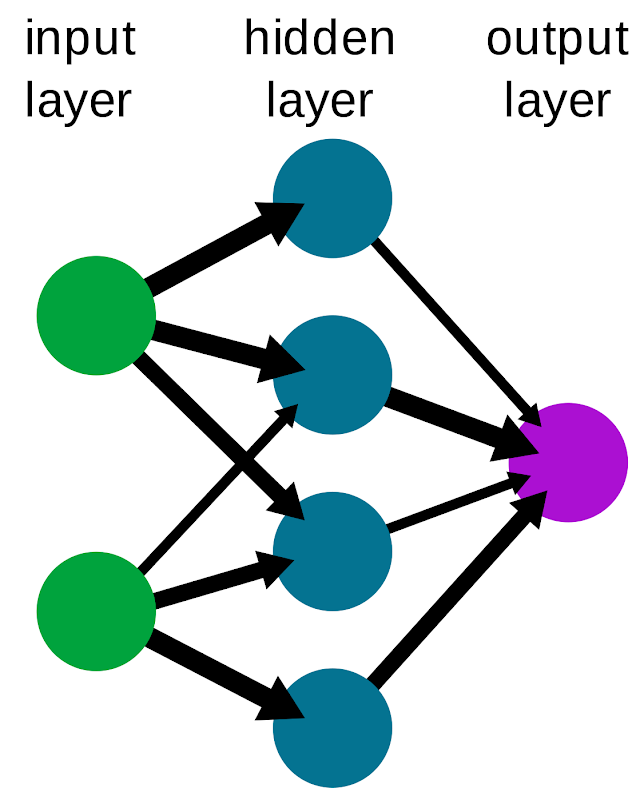
(image source: Wikipedia)
Neural networks are a wonder inspired by the human brain’s structure. Their goal? Learning intricate connections between inputs and outputs, leading to dazzling predictions.
Multilayer Perceptron (MLP): Versatility in Prediction
Think of MLP as a multi-stage journey. Information flows through layers, each enhancing complexity. From inputs to hidden layers to outputs, it learns to predict an array of outcomes.
Convolutional Neural Networks (CNN): Visualizing Excellence
When images are the data, CNNs take the stage. Layers dive deep into visual features, capturing details from pixels to patterns, revolutionizing image recognition.
Recurrent Neural Networks (RNN): Grasping Sequential Context
Text and time series data? RNNs thrive on sequential information. They loop back, using past outputs to shape future predictions—perfect for language processing and prediction.
Long Short-Term Memory (LSTM): Tackling Long-Term Dependencies
LSTMs, a special kind of RNN, conquer the vanishing gradient problem. They excel in understanding patterns with long-range dependencies, like language structure or stock trends.
Embracing Backpropagation for Training
Training neural networks is an art, and backpropagation is the brush. It adjusts weights between nodes to minimize prediction errors, guiding networks to accurate forecasts.
Beyond the Basics: Feedforward, Autoencoders, and GANs
Feedforward networks process data in one direction, often seen in simple models. Autoencoders excel in unsupervised learning, while GANs play both creator and critic, generating realistic data.
3. Classification: Decoding Data Categorization
When categories beckon, classification models answer. They master the art of assigning data into predefined groups, with applications spanning marketing, healthcare, and more.
Decision Trees: Mapping Choices
Imagine a tree of decisions, each leading to an outcome. Decision trees excel in categorical prediction. They’re visual, intuitive, and readily interpretable.
Amplifying Accuracy with Random Forests
Why settle for one tree when you can have a forest? Random forests combine multiple decision trees, ironing out individual errors for a robust, accurate prediction.
Naive Bayes: Probability in Play
Bayesian thinking drives Naive Bayes. It calculates probabilities of an event based on prior knowledge, excelling in situations where variables are independent.
Embracing Distances: SVM and KNN
Support Vector Machines and K-Nearest Neighbors find patterns by measuring distances. They’re powerful allies in deciphering complex data relationships.
4. Clustering: Unearthing Hidden Patterns
Clustering unearths hidden groupings in data. When categories aren’t predefined, clustering helps spot underlying patterns, from market trends to customer behaviors.
K-means Clustering: Grouping by Proximity
K-means divides data into clusters based on closeness. It’s like arranging similar puzzle pieces together, revealing groups that might not be initially obvious.
Hierarchical Clustering: Nurturing Nested Clusters
Hierarchical clustering organizes clusters into a tree, allowing for nuanced insights. It’s like nesting Russian dolls—clusters within clusters, revealing intricate relationships.
Density-Based Clustering: Embracing Density Insights
Density-based clustering cares about data points’ closeness, not just distance. It shines in unevenly distributed data, capturing dense regions effectively.
5. Time Series: Navigating Temporal Trends
When data evolves over time, time series models come to the rescue. They forecast future values by unraveling hidden patterns within historical trends.
ARIMA: Balancing Autoregression and Moving Averages
ARIMA examines past values, combining autoregression (dependence on past values) with moving averages (smoothing out noise). It’s a powerful tool for predicting stock prices and more.
Exponential Smoothing: Weighing the Past
Exponential smoothing prioritizes recent data while giving less weight to distant pasts. It’s fantastic for short-term predictions, especially when abrupt changes occur.
The Magic of Seasonal Decomposition
Seasonal decomposition dissects time series into components—seasonal, trend, and residual. By understanding these building blocks, predictions become more insightful.
6. Decision Trees: Choices and Consequences
Decision trees are like flowcharts, breaking down decisions into a series of choices. At each node, a predictor variable is considered, leading to a prediction.
The Decision Tree Structure
Nodes, branches, and leaves—this is the anatomy of a decision tree. Every step offers choices, guiding the prediction process based on input values.
Versatility in Task: Classification and Regression
Decision trees adapt to various tasks. In classification, they assign categories, while in regression, they predict numerical values.
Navigating CART, CHAID, ID3, and C4.5
Different algorithms, such as CART, CHAID, ID3, and C4.5, fuel decision tree growth. They select variables and split points using measures like Gini impurity and information gain.
7. Ensemble Techniques: Amplifying Accuracy and Stability
Ensemble techniques unite individual models, elevating accuracy and stability. By combining diverse perspectives, they tackle complexity and produce robust predictions.
Bagging: Aggregating for Stability
Bagging creates multiple models, each trained on a different subset of data. By blending their predictions, bagging reduces model variance and hones accuracy.
Boosting: Correcting and Enhancing
Boosting builds models sequentially. Each new model corrects errors of its predecessor, collectively improving predictive accuracy.
Stacking: Harnessing Collective Wisdom
Stacking combines various models’ predictions, funneling them through a meta-model to refine the final prediction. It capitalizes on different models’ strengths.
The Might of Random Forest
Random Forest is a bagging technique enhanced by decision trees. By aggregating numerous tree predictions, it delivers accurate and robust results.
Predictive analytics is a remarkable journey that bridges data and predictions, transforming raw information into actionable insights. From the elegance of regression to the intricacies of neural networks, and from classification’s clarity to clustering’s revelation, the toolkit of models at your disposal is vast and versatile. And through the power of ensemble methods, the sum is truly greater than its parts.